BERT: The AI Revolution In Language Understanding Explained
BERT (Bidirectional Encoder Representations from Transformers) has fundamentally reshaped the landscape of natural language processing (NLP). Introduced by researchers at Google in October 2018, this groundbreaking language model marked a significant leap forward in how machines comprehend and generate human language. Its arrival signaled a new era, moving beyond traditional, often unidirectional, approaches to text understanding.
The innovation behind BERT lies in its ability to process language contextually from both directions simultaneously, a capability that was largely absent in previous models. This bidirectional understanding allows BERT to grasp the nuances of words based on their surrounding text, leading to unprecedented accuracy in a wide array of NLP tasks. This article will delve into what BERT is, how it operates, and why it stands as a pivotal innovation in the world of artificial intelligence.
Table of Contents
- Understanding BERT: The Core Concept
- The Revolutionary Architecture of BERT
- Pre-training BERT: Learning from Unlabeled Text
- BERT's Superiority: Why It Outperforms Others
- The Mechanics of BERT: Input and Output Processing
- Scaling BERT: Variants and Parameters
- Applications and Impact of BERT in NLP
- The Enduring Legacy of BERT
Understanding BERT: The Core Concept
To truly appreciate the impact of BERT, it's essential to grasp its fundamental nature and the innovative approach it brought to the field of natural language processing. Before BERT, many language models struggled with fully understanding the context of words, often processing text in a single direction.
What is BERT?
At its heart, BERT stands for Bidirectional Encoder Representations from Transformers. This name itself provides significant clues about its design and functionality. Introduced by Google researchers in October 2018, BERT is not just another language model; it's a pre-training technique for NLP that has revolutionized how machines learn to represent text. Unlike previous models that might only look at words from left-to-right or right-to-left, BERT processes words in relation to all other words in a sentence simultaneously. This comprehensive understanding allows it to learn deep contextual relationships between words, which is crucial for accurate language interpretation.
The model learns to represent text as a sequence of numerical vectors, known as embeddings. These embeddings are not static; they change based on the context of the word within a sentence. For instance, the word "bank" would have different embeddings if it appeared in "river bank" versus "financial bank," reflecting its distinct meanings. This dynamic representation is a cornerstone of BERT's effectiveness, enabling it to capture the subtle nuances and ambiguities inherent in human language.
Why "Bidirectional"?
The "Bidirectional" aspect of BERT is arguably its most significant innovation. Prior to BERT, models like Word2Vec or GloVe generated static word embeddings, meaning a word always had the same representation regardless of its context. Later models like ELMo introduced contextual embeddings but were often unidirectional or combined two separate unidirectional passes. This meant they might process a sentence from left to right, then from right to left, and combine the results, but they didn't inherently consider both contexts simultaneously for each word during the core processing.
BERT, however, truly is bidirectional. It processes the entire sequence of words at once, allowing each word's representation to be influenced by all other words in the sentence, both preceding and succeeding it. This holistic view is critical for understanding polysemy (words with multiple meanings) and for resolving ambiguities in sentences. For example, in the sentence "The bear can bear a heavy load," a unidirectional model might struggle to differentiate between the animal "bear" and the verb "bear." BERT's bidirectional nature, powered by the Transformer architecture, enables it to grasp these distinctions effortlessly by considering the full context.
The Revolutionary Architecture of BERT
The power of BERT doesn't just come from its bidirectional nature; it's intricately linked to the underlying neural network architecture it employs: the Transformer. This architecture, itself a breakthrough introduced by Google in 2017, laid the groundwork for BERT's remarkable capabilities.
Transformer Power: The Foundation
BERT is essentially composed of multiple layers of the Transformer's encoder stack. The Transformer architecture moved away from traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) for sequence modeling, primarily by introducing the concept of "attention." Specifically, the Transformer relies heavily on a mechanism called "self-attention." This mechanism allows the model to weigh the importance of different words in the input sequence when processing a specific word. For instance, when processing the word "it" in a sentence like "The cat sat on the mat. It purred.", the self-attention mechanism helps BERT understand that "it" refers to "the cat."
The Transformer's ability to process input sequences in parallel, rather than sequentially like RNNs, significantly speeds up training times and allows for the handling of much longer sequences. This efficiency and the effectiveness of the attention mechanism are what make the Transformer a powerful foundation for language models, and BERT leverages this power to its fullest extent. The "Data Kalimat" explicitly mentions that BERT is "multi-layered Transformer Encoder堆叠成的" (stacked by multi-layered Transformer Encoders), underscoring this foundational aspect.
Bidirectional Encoding Explained
As mentioned, BERT's bidirectional nature is key. This is achieved through the Transformer's self-attention mechanism. Unlike previous models that would process text sequentially, the self-attention mechanism in BERT allows each word to simultaneously attend to all other words in the input sequence. This means that when BERT is generating a representation for a particular word, it considers the entire context—both words that come before it and words that come after it.
This "captures context" capability is what truly sets BERT apart. For example, if you have the sentence "The boy saw a bat," the word "bat" can mean an animal or a piece of sports equipment. A traditional left-to-right model might not fully resolve this ambiguity until it reaches the end of the sentence or even later context. BERT, by looking at the entire sentence at once, can better infer the intended meaning by considering all surrounding words. This dual-directional contextual understanding is precisely what enables BERT to significantly enhance language understanding tasks, making it a groundbreaking model in NLP.
Pre-training BERT: Learning from Unlabeled Text
One of the most innovative aspects of BERT is its pre-training methodology. Instead of being trained for a specific task from scratch, BERT undergoes extensive pre-training on massive amounts of unlabeled text data. This pre-training phase teaches the model a deep understanding of language structure, grammar, and semantics, which can then be fine-tuned for various downstream NLP tasks with relatively little additional data.
Masked Language Model (MLM)
The first and most crucial pre-training task for BERT is the Masked Language Model (MLM). In this task, a certain percentage (typically 15%) of the tokens (words or sub-word units) in the input sentences are randomly "masked" or hidden. The goal of the model is then to predict the original identity of these masked tokens based on the context provided by the unmasked words. This is a powerful way to force the model to learn bidirectional context. Because BERT must predict a masked word by looking at words to its left and right, it inherently develops a deep, non-directional understanding of language. This contrasts sharply with traditional language models that predict the next word in a sequence, which inherently limits their contextual understanding to a single direction.
Next Sentence Prediction (NSP)
The second pre-training task is Next Sentence Prediction (NSP). This task helps BERT understand the relationship between two sentences. During pre-training, the model is given pairs of sentences. For half of the pairs, the second sentence truly follows the first in the original document. For the other half, the second sentence is a random sentence pulled from the corpus. BERT's task is to predict whether the second sentence logically follows the first. This seemingly simple task is vital for applications that require understanding discourse coherence, such as question answering, where the model needs to determine if a given answer sentence is relevant to a preceding question.
Together, MLM and NSP enable BERT to learn rich, contextual representations of words and sentences. This pre-training on unlabeled text is what makes BERT so versatile and powerful, allowing it to achieve state-of-the-art results across a wide range of NLP benchmarks after minimal fine-tuning.
BERT's Superiority: Why It Outperforms Others
The introduction of BERT marked a clear turning point in NLP, demonstrating superior performance over its predecessors. This wasn't just a marginal improvement; it was a significant leap forward, largely attributable to its architectural design and pre-training methodology.
Beyond ELMo: The Architectural Advantage
The provided "Data Kalimat" explicitly notes why BERT outperforms ELMo (Embeddings from Language Models), another prominent contextual embedding model that preceded BERT. The key reasons highlighted are: "LSTM 抽取特征的能力远弱于 Transformer; 拼接方式双向融合的特征." This translates to: "LSTM's feature extraction capability is far weaker than Transformer; the feature fusion method of splicing is bidirectional."
- Transformer vs. LSTM: ELMo relied on Long Short-Term Memory (LSTM) networks, a type of recurrent neural network. While LSTMs were a significant improvement over basic RNNs for handling sequential data, they still process information sequentially. This inherent sequential nature makes them less efficient and less capable of capturing long-range dependencies and complex contextual relationships compared to the parallel processing and attention mechanisms of the Transformer. The Transformer's ability to weigh the importance of all words simultaneously, regardless of their distance, gives it a distinct advantage in feature extraction.
- True Bidirectional Fusion: ELMo achieved bidirectionality by training two separate LSTMs—one forward and one backward—and then concatenating their outputs. While this provided contextual embeddings, it wasn't a truly integrated bidirectional understanding at the core processing level. BERT, on the other hand, uses the Transformer's self-attention to inherently process context from both directions simultaneously within a single model. This means that each word's representation is formed by considering its entire context in a deeply integrated manner, leading to richer and more accurate contextual embeddings. This holistic approach to contextual understanding is a major reason for BERT's enhanced performance.
Deep Contextual Understanding
The combination of the Transformer architecture and the bidirectional pre-training tasks (MLM and NSP) allows BERT to achieve a truly deep contextual understanding of language. Previous models often struggled with polysemy (words with multiple meanings) or understanding the relationship between sentences. BERT's ability to predict masked words based on full context and to determine sentence relationships directly addresses these challenges.
This deep understanding translates into significantly enhanced performance across a multitude of NLP tasks. Whether it's understanding search queries, summarizing documents, translating languages, or classifying text, BERT's pre-trained knowledge base and its capacity to capture subtle contextual cues have set new benchmarks. It has revolutionized language understanding by providing a robust and versatile foundation for virtually any language-related AI application.
The Mechanics of BERT: Input and Output Processing
Understanding how BERT processes input and output text is crucial for anyone looking to leverage its capabilities. The model requires specific formatting for its input and produces outputs that can be interpreted for various downstream tasks.
Tokenization and Input Formatting
Before any text can be fed into BERT, it undergoes a crucial pre-processing step called tokenization. BERT typically uses a WordPiece tokenizer. This tokenizer breaks down words into sub-word units, which helps handle out-of-vocabulary words and reduces the overall vocabulary size while still maintaining semantic meaning. For example, "unbelievable" might be tokenized into "un", "##believe", "##able".
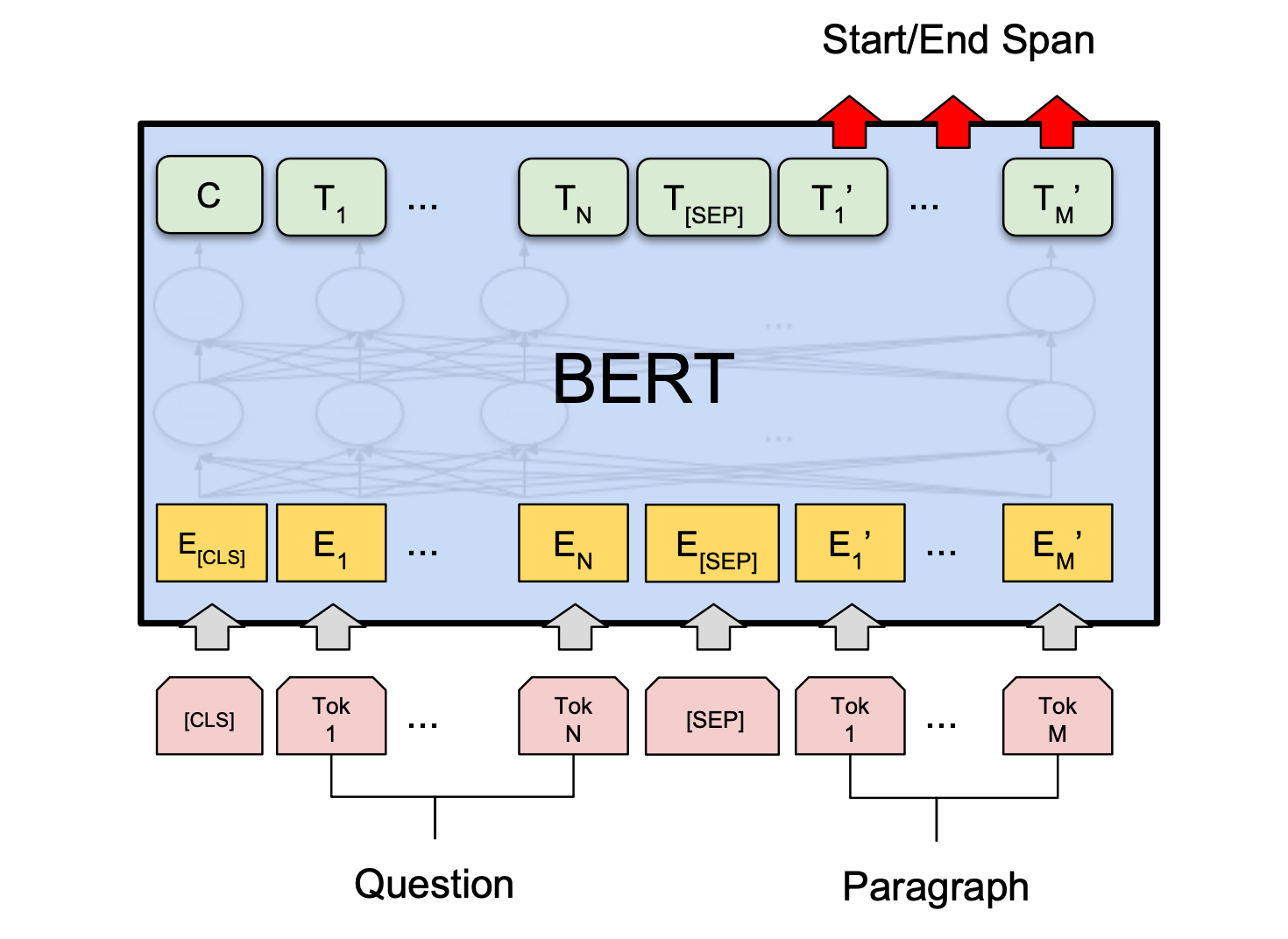
Beyond tokenization, BERT requires specific input formatting. Each input sequence (whether a single sentence or a pair of sentences) is structured with special tokens:
[CLS]: A special classification token inserted at the beginning of every input sequence. Its final hidden state (the output vector corresponding to this token) is used as the aggregate sequence representation for classification tasks.[SEP]: A separator token used to mark the end of a sentence or to separate two distinct sentences in a pair (e.g., for Next Sentence Prediction or question-answering tasks where you have a question and a passage).
How BERT Processes Text
Once the input text is tokenized and formatted, it passes through the multi-layered Transformer encoder. As discussed, the core of this processing is the self-attention mechanism, which allows each token to interact with every other token in the sequence, creating a rich contextual representation for each. This means that for every input token, BERT outputs a corresponding contextualized embedding vector.
These output embeddings are what make BERT so versatile. For different NLP tasks, different parts of BERT's output are utilized:
- Classification Tasks: For tasks like sentiment analysis or spam detection, the final hidden state corresponding to the
[CLS]token is typically used. This vector is considered to be an aggregate representation of the entire input sequence, which can then be fed into a simple classification layer (e.g., a softmax layer) to predict a label. - Token-Level Tasks: For tasks like Named Entity Recognition (NER) or part-of-speech tagging, the output embeddings for each individual token are used. Each token's embedding can then be fed into a classification layer to predict a label for that specific token.
- Question Answering: For extractive question answering, BERT predicts the start and end positions of the answer within a given passage. This involves taking the output embeddings of the passage tokens and training a small layer on top to predict the likelihood of each token being a start or an end of an answer span.
Scaling BERT: Variants and Parameters
BERT was not released as a single, monolithic model. Instead, Google provided different versions, allowing users to choose the model size that best fits their computational resources and specific task requirements. These variants demonstrate the scalability and adaptability of the BERT architecture.
BERT Base vs. Large
The original BERT paper introduced two main model sizes: BERT Base and BERT Large. The "Data Kalimat" specifically mentions the parameters of BERT Base: "24 transformer layers, 1024 hidden units, 16 attention heads (340m parameters)." This description, however, seems to combine elements of both. The typical BERT Base model has:
- BERT Base: 12 Transformer layers, 768 hidden units, 12 attention heads, and approximately 110 million parameters.
- BERT Large: 24 Transformer layers, 1024 hidden units, 16 attention heads, and approximately 340 million parameters.
Adaptability Across Tasks
One of BERT's most compelling features is its remarkable adaptability. Because it is pre-trained on a vast corpus of unlabeled text to learn general language representations, it can be fine-tuned for a wide array of downstream NLP tasks with relatively small, task-specific datasets. This paradigm shift, from training models from scratch for each task to pre-training a large model and then fine-tuning it, has significantly accelerated progress in NLP.
BERT serves as the basis for an entire ecosystem of applications and further research. Its pre-trained weights provide a powerful starting point, allowing developers and researchers to achieve state-of-the-art results on tasks like:
- Text classification (e.g., spam detection, sentiment analysis)
- Question answering (e.g., finding answers in documents)
- Named Entity Recognition (e.g., identifying names of people, organizations, locations)
- Text summarization
- Machine translation
- And many more complex language understanding tasks.
Applications and Impact of BERT in NLP
Since its release, BERT has profoundly impacted the field of Natural Language Processing, moving from a research breakthrough to a practical tool integrated into numerous real-world applications. Its ability to deeply understand context has unlocked new levels of accuracy and efficiency.
Enhanced Search and Question Answering
Perhaps one of the most visible impacts of BERT has been its integration into Google Search. In 2019, Google announced that BERT was being used to better understand search queries, especially complex or conversational ones. This means that when you type a query, Google's search engine, powered by BERT, can better grasp the nuances and intent behind your words, leading to more relevant search results. For example, if you search for "Can you get medicine for someone at the pharmacy?", BERT helps the search engine understand that "for someone" is crucial, and it's not asking if *you* can get medicine, but if you can pick it up on behalf of another person.
Similarly, BERT has dramatically improved question-answering systems. Whether it's a chatbot providing customer support or a system extracting answers from large documents, BERT's contextual understanding allows it to pinpoint precise answers. It can read a passage, understand the question, and identify the exact span of text that contains the answer, rather than just returning a document or a loosely related paragraph.
Improved Text Classification and Sentiment Analysis
Text classification, a fundamental NLP task that involves categorizing text into predefined classes, has seen significant improvements with BERT. From spam detection and content moderation to topic classification, BERT's ability to generate rich, contextual embeddings for entire sentences or documents leads to highly accurate classifications. Businesses can now more effectively sort customer feedback, identify trending topics in news articles, or filter out inappropriate content with greater precision.
Sentiment analysis, a specific form of text classification that determines the emotional tone of a piece of text (positive, negative, neutral), has also benefited immensely. Understanding sentiment requires a deep grasp of context, irony, and sarcasm, which traditional models often struggled with. BERT's bidirectional nature allows it to better detect these subtleties, providing more reliable insights into customer reviews, social media posts, and public opinion.
- What Is The Zodiac Sign For November 12
- Celebrity Nip Slip
- Classic Sonic
- Tadashi Hamada
- Leeann Tweeden
An Introduction to BERT And How To Use It | BERT_Sentiment_Analysis
![BERT Explained: SOTA Language Model For NLP [Updated]](https://www.labellerr.com/blog/content/images/2023/05/bert.webp)
BERT Explained: SOTA Language Model For NLP [Updated]

Bert - Muppet Wiki
